简述sigmoid激活函数的性质(激活函数具有哪些性质)
 狂丶刀
狂丶刀- 旅游
- 2023-04-05 23:46:07
- -
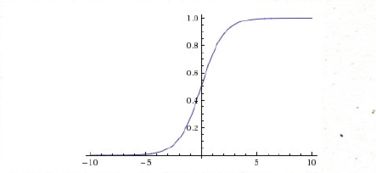
一.激活函数(activation functions)
激活函数通常有如下一些性质:
非线性: 当激活函数是非线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即f(x)=xf(x)=x),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
f(x)≈xf(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
通过上面的介绍,我们对激活函数大体上有了一个认识。
联系之前学习过的机器学习理论,激活函数和核函数的作用简直是异曲同工!都是在不改变线性模型的条件下,将输出结果转变为非线性。
sigmod函数、tanh函数、修正线性单元ReLU函数、Leaky ReLU、参数化ReLU、随机化ReLU、指数化线性单元ELU函数和PReLU函数。
具体介绍参考如下文章:
激活函数又称为“”非线性映射函数“,是深度卷积神经网络不可或缺的模块。
直观上,激活函数模仿了生物神经元特性,接受一组输入信号并产生输出。
(1)激活函数对深度网络模型引入非线性;
(2)Sigmoid型函数是最早的激活函数之一,但它和tanh(x)型函数一样,会产生梯度饱和现象,故实际工程中很少使用;
(3)建议使用目前最常用的ReLU函数,但需注意模型参数初始化和学习率的设定;
(4)其他几种ReLU函数实际性能并无优劣,应结合实际场景具体讨论。
激活函数
参考 :
非线性激活函数能够使神经网络逼近任意复杂的函数。如果没有激活函数引入的非线性,多层神经网络就相当于单层的神经网络
sigmoid
1、梯度消失:sigmoid函数在0和1附近是平坦的。也就是说,sigmoid的梯度在0和1附近为0。在通过sigmoid函数网络反向传播时,当神经元的输出近似于0和1时它的梯度接近于0。这些神经元被称为饱和神经元。因此,这些神经元的权值无法更新。不仅如此,与这些神经元相连接的神经元的权值也更新得非常缓慢。这个问题也被称为梯度消失。所以,想象如果有一个大型网络包含有许多处于饱和动态的sigmoid激活函数的神经元,那么网络将会无法进行反向传播。
2、不是零均值:sigmoid的输出不是零均值的。
3、计算量太大:指数函数与其它非线性激活函数相比计算量太大了。下一个要讨论的是解决了sigmoid中零均值问题的非线性激活函数。
Sigmoid 和 Softmax 区别:
sigmoid将一个real value映射到(0,1)的区间,用来做二分类。而 softmax 把一个 k 维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中 bi 是一个 0~1 的常数,输出神经元之和为 1.0,所以相当于概率值,然后可以根据 bi 的概率大小来进行多分类的任务。二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss,而 softmax 可以用于多分类问题多个logistic回归通过叠加也同样可以实现多分类的效果,但是 softmax回归进行的多分类,类与类之间是互斥的,即一个输入只能被归为一类;多个logistic回归进行多分类,输出的类别并不是互斥的,即"苹果"这个词语既属于"水果"类也属于"3C"类别。
tanh
Tanh唯一的缺点是:tanh函数也存在着梯度消失的问题,因此在饱和时会导致梯度消失。为了解决梯度消失问题,让我们讨论另一个被称为线性整流函数(ReLU)的非线性激活函数,它比我们之前讨论的两个激活函数都更好,并且也是在今天应用最为广泛的激活函数。
ReLU
用形式化的语言来说,所谓****非线性 ,就是一阶导数不为常数 。 ReLu 的定义是max(0, x),因此, ReLU 的导数为:
显然, ReLU 的导数不是常数,所以 ReLU 是 非线性 的。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
1、ReLu虽然在大于0的区间是线性的,在小于等于0的部分也是线性的, 但是它整体不是线性的,因为不是一条直线,所以Relu函数是非线性函数 。也就是说,线性和 非线性 都是就 函数 的整体而言的。用术语来说, 线性、 非线性 是就 函数 的整个定义域而言的。 这就意味着无论我们堆多少层网络,如果这些层都使用线性激活 函数 ,那这些层最终等效于一层!那这样的模型的表达能力就很 有 限了。多个线性操作的组合也是一个线性操作,没有非线性激活,就相当于只有一个超平面去划分空间。
ReLu是非线性的,效果类似于划分和折叠空间,组合多个(线性操作 + ReLu)就可以任意的划分空间 。
2、对于浅层的机器学习,比如经典的三层神经网络,用它作为激活函数的话,那表现出来的性质肯定是线性的。但是在深度学习里,少则几十,多则上千的隐藏层,虽然,单独的隐藏层是线性的,但是很多的隐藏层表现出来的就是非线性的。举个简单的例子,一条曲线无限分段,每段就趋向直线,反过来,很多这样的直线就可以拟合曲线。类似,大规模的神经网络,包含很多这样的线性基本组件,自然也可以拟合复杂的非线性情况。Relu通过构造很多的线形空间(类似于折叠的方式),逼近非线性方程。
但是Relu神经元有几个缺点:
平时使用的时候RELU的缺点并不是特别明显,只有在学习率设置不恰当(较大)的时候,会加快神经网络中神经元的“死亡”。
为了解决relu激活函数在x0时的梯度消失问题, 提出了Leaky Relu
leaky ReLU
pReLU
PRelu的函数为:
其中α为超参数。PRelu的思想是引进任意超参数α ,而 这个α可以通过反向传播学习(注意 PRelu 与leaky relu的区别,前者是学习得到,后者是我们认为设定) 。这赋予了神经元在负区域内选择最好斜率的能力,因此,他们可以变成单纯的ReLU激活函数或者Leaky ReLU激活函数。如果α=0,那么 PReLU 退化为ReLU;如果α是一个很小的固定值(如α =0.01),则 PReLU 退化为 Leaky ReLU(LReLU)。
(1) PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的, 当不同channels使用相同的ai时,参数就更少了。
(2) BP更新ai时,采用的是带动量的更新方式:
总之, 一般使用ReLU效果更好 ,但是你可以通过实验使用Leaky ReLU或者Parametric ReLU来观察它们是否能对你的问题给出最好的结果。
ELU
SELU
经过该激活函数后使得样本分布自动归一化到0均值和单位方差(自归一化,保证训练过程中梯度不会爆炸或消失,效果比Batch Normalization 要好)
其实就是ELU乘了个lambda,关键在于这个lambda是大于1的。以前relu,prelu,elu这些激活函数,都是在负半轴坡度平缓,这样在activation的方差过大的时候可以让它减小,防止了梯度爆炸,但是正半轴坡度简单的设成了1。而selu的正半轴大于1,在方差过小的的时候可以让它增大,同时防止了梯度消失。这样激活函数就有一个不动点,网络深了以后每一层的输出都是均值为0方差为1。
swish
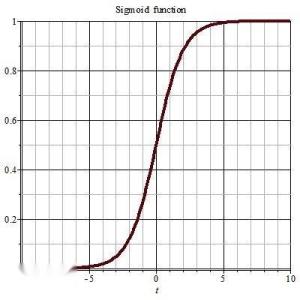
激活函数总结
什么是激活函数
激活函数在神经网络当中的作用**是赋予神经网络更多的非线性因素。如果不用激活函数,网络的输出是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限。如果能够引入恰当的非线性函数作为激活函数,这样神经网络逼近能力就能够更加强大。
激活函数(Activation functions)对于神经网络模型学习与理解复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。
如果网络中不使用激活函数,网络每一层的输出都是上层输入的线性组合,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,此时神经网络就可以应用到各类非线性场景当中了。
常见的激活函数如sigmoid、tanh、relu等,它们的输入输出映射均为非线性,这样才可以给网络赋予非线性逼近能力。
下图为Relu激活函数,由于在0点存在非线性转折,该函数为非线性激活函数:
常用的激活函数
1、Sigmoid
Sigmoid函数是一个在生物学中常见的S型函数,它能够把输入的连续实值变换为0和1之间的输出,如果输入是特别小的负数,则输出为0,如果输入是特别大的正数,则输出为1。即将输入量映射到0到1之间。
Sigmoid可以作为非线性激活函数赋予网络非线性区分能力,也可以用来做二分类。其计算公式为:
曲线过渡平滑,处处可导;
缺点:
幂函数运算较慢,激活函数计算量大;
求取反向梯度时,Sigmoid的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
2、Tanh
Tanh是一个奇函数,它能够把输入的连续实值变换为-1和1之间的输出,如果输入是特别小的负数,则输出为-1,如果输入是特别大的正数,则输出为1;解决了Sigmoid函数的不是0均值的问题。
曲线过渡平滑,处处可导;
具有良好的对称性,网络是0均值的。
缺点:
与Sigmoid类似,幂函数运算较慢,激活函数计算量大;
与Sigmoid类似,求取反向梯度时,Tanh的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
3、ReLU
线性整流函数(Rectified Linear Unit, ReLU),是一种深度神经网络中常用的激活函数,整个函数可以分为两部分,在小于0的部分,激活函数的输出为0;在大于0的部分,激活函数的输出为输入。计算公式为:
收敛速度快,不存在饱和区间,在大于0的部分梯度固定为1,有效解决了Sigmoid中存在的梯度消失的问题;
计算速度快,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的指数运算,具有类生物性质。
缺点:
它在训练时可能会“死掉”。如果一个非常大的梯度经过一个ReLU神经元,更新过参数之后,这个神经元的的值都小于0,此时ReLU再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0。合理设置学习率,会降低这种情况的发生概率。
先进的激活函数
1、LeakyReLU
LeakyReLU具有ReLU的优点;
解决了ReLU函数存在的问题,防止死亡神经元的出现。
缺点:
α参数人工选择,具体的的值仍然需要讨论。
2、PReLU
PReLU具有LeakyReLU的优点;
解决了LeakyReLU函数存在的问题,让神经网络自适应选择参数。
3、ReLU6
ReLU6就是普通的ReLU但是限制最大输出为6,用在MobilenetV1网络当中。目的是为了适应float16/int8 的低精度需要
优点:
ReLU6具有ReLU函数的优点;
该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。如果对 ReLU 的激活范围不加限制,激活值非常大,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
缺点:
与ReLU缺点类似。
4、Swish
Swish是Sigmoid和ReLU的改进版,类似于ReLU和Sigmoid的结合,β是个常数或可训练的参数。Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。
优点:
Swish具有一定ReLU函数的优点;
Swish具有一定Sigmoid函数的优点;
Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
运算复杂,速度较慢。
5、Mish
Mish与Swish激活函数类似,Mish具备无上界有下界、平滑、非单调的特性。Mish在深层模型上的效果优于 ReLU。无上边界可以避免由于激活值过大而导致的函数饱和。
优点:
Mish具有一定ReLU函数的优点,收敛快速;
Mish具有一定Sigmoid函数的优点,函数平滑;
Mish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
运算复杂,速度较慢。
5、Swish和Mish的梯度对比。
原文链接:
[img]sigmoid有什么作用
什么是sigmoid?其作用是什么?很简单。这是一个科学家发明的数学工具。我们在做决策的时候通常非此即彼。在计算机中通常用零或一来替代两种可能性。为了勾画决策的不确定性。可以使用0到1之间的一个实数来表示我们决策的结果。这样当我们的决策结果是0.6的时候。代表我们更倾向于选择1更不倾向于选择0。
然而现实中我们所观察到的特征,通常不是0到1之间的实数。我们要做决策,就必须将这个实数压缩到0到1之间。
假设我们有若干客户的消费记录。想判断哪些客户是高收入人群,哪些客户是低收入人群。
一个比较简单的方法就是计算每个客户的平均消费金额。当平均消费金额大于一个特定的阈值a时,则为高收入人群,小于则为低收入人群。
这显然是一个非此即彼判断。没有表现出决策的不确定性。
为了引入决策的不确定性,我们必须给每一种平均消费金额给予一个打分。这个打分在0到1之间。也可以理解为是决策的概率。
我们完全可以把平均消费金额作为sigmoid函数的输入,从而将任意金额映射到0到1之间。
这个sigmoid函数有两个参数来控制着决策不确定性的映射。第一个参数的取值决定了sigmoid函数将怎样的平均消费金额映射为0.5,即完全不确定。该参数的取值类似于上文提到的阈值a。
另外一个参数和sigmoid函数的性质有关。sigmoid函数有如下性质当平均消费金额远大于a时函数的输出结果无限逼近于一。当平均消费金额远小于a时函数的输出结果无限逼近于零。
则另外一个参数实际上控制着这个逼近速度。当这个逼近速度无限大的时候,就等同于上面简单的方案。而这当这个逼近速度比较慢的时候,其会以较细的粒度描述决策的不确定性。即针对各种平均消费金额其都不会草率的将其无限逼近于零或者一。而是给定一个0到1之间的合适的实数值。
这就是sigmoid函数全部的作用了。
激活函数 sigmoid、tanh、relu
连续的:当输入值发生较小的改变时,输出值也发生较小的改变;
可导的:在定义域中,每一处都是存在导数;
激活函数
常见的激活函数:sigmoid,tanh,relu。
sigmoid
sigmoid是平滑(smoothened)的阶梯函数(step function),可导(differentiable)。sigmoid可以将任何值转换为0~1概率,用于二分类。细节可以 参考 。
公式:
导数:
导数2:
图(红色原函数,蓝色导函数):
sigmoid
当使用sigmoid作为激活函数时,随着神经网络隐含层(hidden layer)层数的增加,训练误差反而加大。表现为:
靠近输出层的隐含层梯度较大,参数更新速度快,很快就会收敛;
靠近输入层的隐含层梯度较小,参数更新速度慢,几乎和初始状态一样,随机分布;
在含有四个隐藏层的网络结构中,第一层比第四层慢了接近100倍!
这种现象就是梯度弥散(vanishing gradient)。而另一种情况,梯度爆炸(exploding gradient),则是前面层的梯度,通过训练变大,导致后面层的梯度,以指数级增大。
sigmoid的更新速率
由于sigmoid的导数值小于1/4,x变化的速率要快于y变化的速率,随着层数的增加,连续不断执行sigmoid函数,就会导致,前面更新较大的幅度,后面更新较小的幅度,因此,网络在学习过程中,更倾向于,更新后面(靠近输出层)的参数,而不是前面的参数(靠近输入层)。
sigmoid的导函数
sigmoid缺点:
激活函数的计算量较大,在反向传播中,当求误差梯度时,求导涉及除法;
在反向传播中,容易就会出现梯度消失,无法完成深层网络的训练;
函数的敏感区间较短,(-1,1)之间较为敏感,超过区间,则处于饱和状态,
参考1 、 参考2
tanh
tanh,即双曲正切(hyperbolic tangent),类似于幅度增大sigmoid,将输入值转换为-1至1之间。tanh的导数取值范围在0至1之间,优于sigmoid的0至1/4,在一定程度上,减轻了梯度消失的问题。tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP(back propagation)网络的梯度求解,容错性好,有界。
公式:
导数:
图(红色原函数,蓝色导函数):
tanh
sigmoid和tanh:
sigmoid在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值;
tanh的变化敏感区间较宽,导数值渐进于0、1,符合人脑神经饱和的规律,比sigmoid函数延迟了饱和期;
tanh在原点附近与y=x函数形式相近,当激活值较低时,可以直接进行矩阵运算,训练相对容易;
tanh和sigmoid都是全部激活(fire),使得神经网络较重(heavy)。
参考1 、 参考2 、 参考3
relu
relu,即Rectified Linear Unit,整流线性单元,激活部分神经元,增加稀疏性,当x小于0时,输出值为0,当x大于0时,输出值为x.
公式:
图:
relu
导数:
图:
ReLU的导函数
relu对比于sigmoid:
sigmoid的导数,只有在0附近,具有较好的激活性,而在正负饱和区的梯度都接近于0,会造成梯度弥散;而relu的导数,在大于0时,梯度为常数,不会导致梯度弥散。
relu函数在负半区的导数为0 ,当神经元激活值进入负半区,梯度就会为0,也就是说,这个神经元不会被训练,即稀疏性;
relu函数的导数计算更快,程序实现就是一个if-else语句;而sigmoid函数要进行浮点四则运算,涉及到除法;
relu的缺点:
在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度,流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。
如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。
在神经网络中,隐含层的激活函数,最好选择ReLU。
关于RNN中为什么选择tanh,而不是relu, 参考 。
本文由作者笔名:狂丶刀 于 2023-04-05 23:46:07发表在本站,原创文章,禁止转载,文章内容仅供娱乐参考,不能盲信。
本文链接:https://www.e-8.com.cn/ly-132782.html
随机推荐

三国志11哪些武将比较厉害()
2022-12-25
小米充电宝3支持pd20w快充吗(小米移动电源3超级闪充版拆解)
2022-12-27
15首春秋时期的《南山南》,唱给你听(转载南山兵哥的喜欢11)
2023-01-14
如何评价杨紫和任嘉伦主演的电视剧《天乩之白蛇传说》(最新白蛇传电视剧杨紫)
2023-01-14
交管12123科三考试费(交管12123科三考试费缴纳 交不了)
2023-03-29
世界十大篮球巨星排名(100个篮球明星的名字)
2023-01-05
梦见自己生病去看医生(梦见医生给自己看病)
2022-12-31
《狼烟遍地》免费在线观看完整版高清,求百度网盘资源(遍地狼烟电影达达兔)
2023-01-08
热门文章
电脑特别卡广告特别多怎么办(电脑太卡老是有广告)
2023-05-07
大脸适合烫什么发型女(大脸女生烫什么头发好看)
2023-06-15
大罗小罗c罗j罗谁厉害(大罗真比c罗强吗)
2023-11-15
战友文工团的简介(军区战友文工团)
2022-12-25
夫妻五行如何匹配
2023-05-31
妈妈的爱的介绍(妈妈的爱3作文)
2023-01-27
如何下载电影保存到手机(如何把电影保存到相册)
2023-01-04
2年级写参加婚礼的日记(参加婚礼写话二年级)
2023-03-11