relu激活函数的作用(relu激活函数是一种线性激活函数)
 人走茶会凉
人走茶会凉- 体育
- 2024-02-13 18:10:01
- -
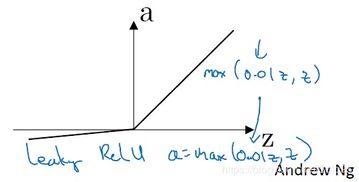
为什么要使用relu激活函数
ReLU 是修正线性单元(rectified linear unit),在 0 和 x 之间取最大值。
为了训练深层神经网络, 需要一个激活函数神经网络,它看起来和行为都像一个线性函数,但实际上是一个非线性函数,允许学习数据中的复杂关系 。该函数还必须提供更灵敏的激活和输入,避免饱和。
激活函数的存在是为了神经网络更好的拟合目标函数而已。
ReLU6就是普通的ReLU但是限制最大输出为6,用在MobilenetV1网络当中。目的是为了适应float16/int8 的低精度需要 优点:ReLU6具有ReLU函数的优点;该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。
可以试试 tanh,不过大多数情况下它的效果会比不上 ReLU 和 Maxout。 如果你不知道应该使用哪个激活函数, 那么请优先选择Relu。
激活函数与损失函数
激活函数:用于增加网络的非线性能力,常见的激活函数有sigmoid、ReLU、tanh等。 损失函数:用于衡量模型预测值与真实值之间的差距,常见的损失函数有均方误差、交叉熵等。
)如果使用sigmoid激活函数,则交叉熵损失函数一般肯定比均方差损失函数好;2)如果是DNN用于分类,则一般在输出层使用softmax激活函数和对数似然损失函数;3)ReLU激活函数对梯度消失问题有一定程度的解决,尤其是在CNN模型中。
深度学习之损失函数与激活函数的选择 在深度神经网络(DNN)反向传播算法(BP)中,我们对DNN的前向反向传播算法的使用做了总结。其中使用的损失函数是均方差,而激活函数是Sigmoid。实际上DNN可以使用的损失函数和激活函数不少。
假设所有的激活函数均为Logistic函数: 。
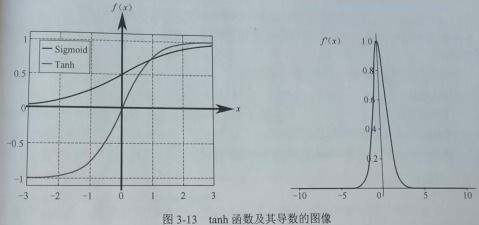
神经网络中ReLU是线性还是非线性函数?如果是线性的话为什么还说它做激活...
但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
在神经网络中,激活函数负责将来自节点的加权输入转换为该输入的节点或输出的激活。ReLU 是一个分段线性函数,如果输入为正,它将直接输出,否则,它将输出为零。
ReLU 是修正线性单元(rectified linear unit),在 0 和 x 之间取最大值。
非线性: 当激活函数是非线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。
Relu激励函数
线性整流函数(Rectified Linear Unit, ReLU),Relu激励函数,也称“热鲁”激励函数。是一种人工神经网络中常见的激活函数。相比于Sigmoid函数,Relu函数的优点:梯度不饱和。梯度计算公式为:1{x0}。
-sigmoid和tanh作为激励函数需要对输入进行规范化处理,否则激活后的值可能进入饱和区,而relu不会出现这种情况,有时relu甚至不需要要求输入规范化,因此目前85%~90%的神经网络会采用relu函数。
ReLU激活函数是一个简单的计算,如果输入大于0,直接返回作为输入提供的值;如果输入是0或更小,返回值0。
ReLU 是修正线性单元(rectified linear unit),在 0 和 x 之间取最大值。
本文由作者笔名:人走茶会凉 于 2024-02-13 18:10:01发表在本站,原创文章,禁止转载,文章内容仅供娱乐参考,不能盲信。
本文链接:https://www.e-8.com.cn/ty-189732.html
随机推荐

林依晨老公是谁 林依晨和林于超是怎么认识的(林依晨老公林于超家世)
2023-01-08
夫妻名字五行互补
2023-06-01
世界上最毒的几种生物(世界上最危险的生物)
2022-12-18
江西文旅厅长李小豹简介(江西省文旅厅陈晓平)
2023-06-12
天河潭烟花秀要门票吗(天河潭烟花秀要门票吗多少钱)
2024-02-02
至今未婚的8位港星,各有各的苦衷,王祖贤陈法蓉在列(李若彤季天笙)
2023-01-12
必背有什么旅游景点(必玩旅游景点)
2023-05-09
车主死亡绿本丢了怎办继承(车主死亡补办绿本需要什么手续)
2023-05-05
热门文章

大浪淘沙周恩来的扮演者(徐箭隋兰)
2023-01-13
叶沐容岩肉(容岩 叶沐 肉)
2023-03-05
这是斯琴丽的伤心高清Mp3(这是斯情的伤心)
2023-05-23
cDK的兑换码是什么(cdkey兑换码)
2022-12-22
索尼相机型号大全是什么(索尼相机型号大全介绍)
2022-12-24
梦回千金小说在哪个app看(梦回1999千禧年小说)
2023-01-07
痛苦女王csol剧情dnf魔枪士三觉时装的简单介绍
2024-02-24
杨幂指责王鸥并说出实情,刘恺威称斗不过杨幂,他们之间究竟发生了什么 (杨幂十大黑历史)
2022-12-20